As AI penetrates more and more areas of our work, study, and life, it’s being used and adopted by people far beyond the tech-savvy among us. So it’s always a good moment to pause, learn, and understand some background: how AI came to be, who invented it, what it is made of, why it consumes so much power, how it works, and what all the associated terms really mean? As this website explores the interactions of AI and humans, focusing on the benefits and improvements AI brings to humanity, it’s only appropriate and humane to continually try to explain AI to people, bringing it ever closer and making it less frightening. AI is not a passing tech fad; it’s here to stay. Suppose we want humanity to evolve and progress together with AI. In that case, it will be inevitable to make AI approachable and digestible for everyone, just as people have learned to watch TV or use their phones. As we have discovered and learned more about ourselves as humans, one aspect that has probably always been the most fascinating and mysterious is the human brain. Scientists have long sought to research and understand this vital organ. As we have been able to enhance our other capabilities with technology over centuries of human evolution, one area remained, until recently, an unknown frontier. We enhanced our ability to move by inventing various vehicles. We enhanced our ability to feed ourselves by domesticating animals and learning to grow crops. We enhanced our ability to see by inventing artificial light. We enhanced our capabilities to produce and build by inventing machines and harnessing electricity. Eventually, we were even able to prolong our physical existence by inventing vaccines and medicines, as well as developing awareness about health and well-being. The last remaining frontier was how to enhance our cognitive capabilities; our thinking, knowledge, and learning. Scientists felt the best approach would obviously be to copy our brains! Our brains consist of billions of brain cells called neurons, organised into different regions of brain tissue. These neurons are famous not only for existing next to each other, like other cells in our body, but also for forming bonds and connections with one another. These connections are used to communicate by sending electrical impulses and various molecules carrying information. One might say they create a network, a neural network. So, what if we tried to mimic this neural network artificially by creating interconnected, tiny electronic circuits that would contain digital ‘cells’ communicating with each other in the language of machines: zeros and ones? If we could copy the brain’s structure in such a way, perhaps we could copy its functioning. This was the reasoning scientists had. The foundational idea for artificial neural networks was proposed as early as 1943 by Warren McCulloch and Walter Pitts. They created a computational model inspired by how neurons in the brain might work, using electrical circuits to simulate neural activity. The first practical breakthrough occurred in 1957, when Frank Rosenblatt, a psychologist at Cornell, developed the Perceptron, a simple, single-layer neural network designed for pattern recognition. Throughout the late 1950s and 1960s, other researchers, such as Bernard Widrow and Marcian Hoff, developed systems that applied neural networks to real-world problems, including echo cancellation in phone lines. However, progress slowed during the 1970s due to limitations in both hardware and algorithms. The real Renaissance began in the 1980s with the development of new learning algorithms, such as backpropagation, which enabled the training of multi-layered (deep) neural networks. However, it was not until significant advancements in electronic technology and the miniaturisation of electronic chips and circuit boards that neural networks reached their full capabilities. Fast forward to 2017, when a team of researchers at Google, led by Ashish Vaswani, published a paper that would transform the AI world: ‘Attention Is All You Need‘. This paper introduced the transformer architecture, a revolutionary way of processing language that would become the foundation for virtually every major AI breakthrough we’ve seen since. What made transformers so revolutionary? Previous AI models processed text sequentially, word by word, like reading a sentence from left to right and trying to remember everything you’d read before. Transformers introduced a mechanism called ‘self-attention’ that enables the model to simultaneously consider all words in a sentence and understand their relationships, regardless of their position. Let’s demystify what happens inside these systems. A neural network is essentially a computing system inspired by biological brains, consisting of interconnected nodes (artificial neurons) arranged in layers. These nodes aren’t physical computer chips, but rather mathematical units implemented in software. Each node performs calculations on the data it receives, applies a mathematical function to determine its output, and passes that result to connected nodes in the next layer, mimicking how real neurons communicate via electrical signals. Here’s how they process information: The magic happens through a process called training, where the network learns from massive amounts of data. During training, the system adjusts millions or even billions of internal parameters (weights) to minimise errors in its predictions. It’s like a student practising problems until they master the underlying patterns. Key concepts you might encounter:How AI came to be
The birth and evolution of neural networks
The revolutionary paper that changed everything
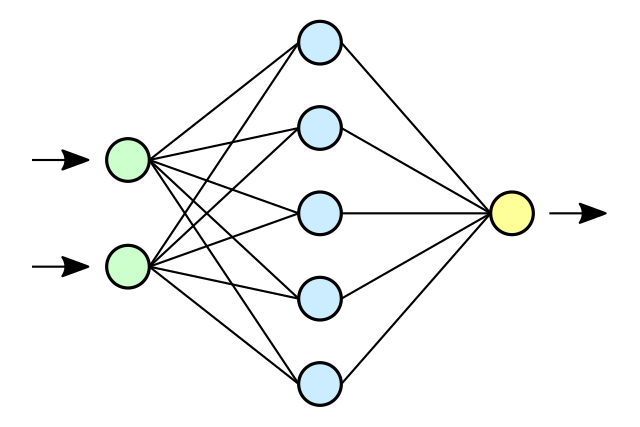
How neural networks actually work
While neural networks dominate today’s AI headlines, there are several other approaches to building intelligent systems that don’t rely on deep learning architectures:
These approaches continue to play important roles in many applications, particularly where interpretability and reliability are crucial, such as in medical diagnosis and financial systems.

Now that we know the foundation, let’s examine how today’s most advanced AI systems operate.
When we say that a Large Language Model (LLM) like ChatGPT or Claude is based on ‘deep learning’, we mean that it uses neural networks with many layers, sometimes dozens or even hundreds, to process and generate language.
Most modern LLMs use transformer architecture, a specialised type of deep neural network that emerged from that revolutionary 2017 Google paper, which processes text (‘transforms’ input text into understanding and output) through several key innovations:
These models learn by training on enormous datasets, often trillions of words from books, websites, and other text sources. During this process, they learn grammar, context, facts about the world, and even reasoning patterns, all by trying to predict the next word in a sequence.
Understanding how AI works helps us appreciate both its capabilities and limitations. These systems are sophisticated pattern recognition and generation tools, trained on human-created content and designed to assist and augment human capabilities.
Whether you’re using ChatGPT for writing assistance, Claude for analysis, or any other AI tool, you’re interacting with implementations of these transformer architectures, all built upon decades of research showing us that, in the realm of language AI, ‘attention is all you need’.
As AI becomes more integrated into our daily lives, this understanding helps us use these tools more effectively while maintaining realistic expectations about what they can and cannot do. The goal isn’t to replace human intelligence, but to enhance it, keeping humans firmly at the centre of our technological progress.
This is the first in a series exploring AI fundamentals from a human-centred perspective. Next, we’ll dive deeper into the terminology and concepts you’ll encounter as AI becomes part of your daily toolkit.
Author: Slobodan Kovrlija