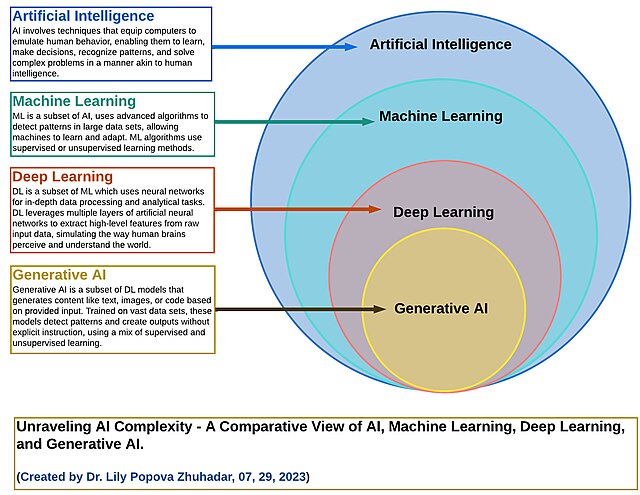
Now that we’ve explored how AI came to be, from biological neurons to artificial neural networks and the transformer revolution, it’s time to understand the vocabulary you’ll encounter as AI becomes part of your daily toolkit. Just as you learned terms like “browser”, “download”, and “WiFi” when the internet became mainstream, there are key AI terms that will help you steer this new technological ecosystem with confidence. These are practical concepts that explain why one AI model might be faster than another, why AI sometimes provides incomplete answers, or why certain tasks work better with different AI systems. Understanding these fundamentals will help you make informed decisions about which AI tools to use and how to use them effectively. When you see AI models described as 7B, 13B, or 70B, those numbers refer to parameters, the internal settings that determine how the AI processes and generates text. Think of parameters as the countless tiny decisions the AI makes when understanding and responding to your input. Imagine parameters as the connections in that neural network we discussed earlier. Each parameter is akin to a single connection between neurons, storing a small piece of learned information about language patterns, word relationships, or knowledge about the world. A 7B model has about 7 billion of these connections, while a 70B model has 70 billion, which is ten times more learning capacity.Parameters: What makes a 7B model different from a 70B?
More parameters generally translate to a better understanding of complex topics, as a 70B model can handle more nuanced conversations and specialised subjects. They also provide more accurate responses since larger models have learned more patterns and make fewer mistakes. Additionally, complex logical thinking requires more neural pathways, so larger models tend to reason more effectively.
However, more isn’t always better for your needs. Smaller models, such as 7B, respond much faster, while larger models require more computational power, often making them more expensive to use. For simple tasks, a 7B model might be perfectly adequate and more practical than a resource-intensive larger model. It’s like choosing between a smartphone and a desktop computer. The desktop might be more powerful, but the smartphone is more convenient for many daily tasks.
When you hear “generative AI”, this refers to AI systems that create new content rather than just analysing or classifying existing information. Unlike earlier AI systems that might identify objects in photos or categorise emails, generative AI produces original text, images, code, music, or other content based on patterns learned during training. The “generative” part means these systems generate something new each time you interact with them. When you ask ChatGPT
to write a poem or Claude to explain a concept, they are not retrieving pre-written responses from a database; they are creating that content fresh, word by word, based on their understanding of language patterns and the specific context of your request.
This is what makes modern AI tools so versatile and powerful. Whether you’re asking for a business email, a creative story, code to solve a problem, or an explanation of quantum physics, you’re interacting with generative AI that can adapt its knowledge to create content tailored to your specific needs. All the major AI systems you encounter today (ChatGPT, Claude, Gemini, and others) are forms of generative AI, specifically generative language models.
When you type a message to ChatGPT or Claude, the AI doesn’t read your words the way you do. Instead, it breaks your text into smaller pieces called tokens. You can see how this works by pasting text into OpenAI’s tokenizer tool. Understanding tokens helps explain many AI behaviours you might have noticed.
In English, one token roughly equals ¾ of a word or about four characters. The sentence “AI is transformative” might be broken into 4-5 tokens. But it’s not as simple as splitting at spaces. AI models use sophisticated tokenisation that can break words into pieces or group multiple words together, depending on what patterns the model learned during training.
Tokens explain several practical limitations you might encounter. Many AI services charge by the token rather than by the word, which affects the cost of your interactions. When an AI seems to cut off mid-sentence, it might have hit its token limit for that response. Additionally, non-English languages often require more tokens for the same meaning, making them more computationally “expensive” to process.
Different languages and content types use tokens differently. Complex formatting like code, mathematical equations, or languages with different writing systems might consume more tokens than plain English text.
Perhaps the most important concept for practical AI use is the context window. Essentially, it’s the AI’s short-term memory or working space. This determines how much information the AI can “keep in mind” at once when generating responses. We can think of the context window as the AI’s workspace that includes both your input (the prompt) and the AI’s response. It’s analogous to a computer’s RAM. Just like RAM allows a computer to hold and quickly access active data, the context window holds your current conversation and relevant information that the AI uses to produce coherent answers.
If you’re having a long conversation or analysing a lengthy document, the AI can only work with information inside this window. When the conversation exceeds the token limit, the earliest parts start to “fall out” of the window, and the AI may “forget” them. This can lead to less accurate responses to questions about earlier parts of your conversation, incomplete analysis of long documents, and inconsistencies in extended interactions.
As of mid-2025, context window sizes vary dramatically:
The jump from a few thousand tokens to millions represents a massive breakthrough. A million-token context window can hold entire books, allowing AI to analyse complete documents, maintain very long conversations, or work with complex multi-part problems without losing track of important details.
While larger context windows offer significant advantages, they come with important considerations. Processing more information requires more computational power, which can slow down response times. Million-token models are expensive to run, often limiting free-tier access and increasing operational costs. Additionally, sometimes extra context doesn’t improve the response quality and might even confuse the model if the additional information isn’t relevant to the task at hand.

The AI world is broadly divided between Large Language Models (LLMs) and Small Language Models (SLMs), but the distinction is more nuanced than simply “big” versus “small”.
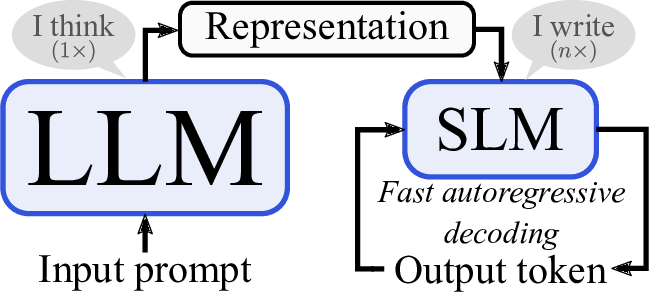
Choose LLMs for tasks requiring deep comprehension, creativity, and broad knowledge across multiple domains. Choose SLMs for targeted applications where speed, cost, and domain expertise are priorities. The choice isn’t always about capability. Sometimes a focused SLM performs better than a general LLM for specific tasks, much like how a specialised tool often works better than a general-purpose one.
Understanding the difference between training and inference helps explain why AI development is so resource-intensive and why your interactions with AI work the way they do.
This distinction explains why models have knowledge cutoffs (they only know information up to their last training date) and why they don’t truly “learn” from your conversation—that’s just the context window at work.
Understanding training versus inference helps explain several important aspects of AI interaction. AI models only know information up to their training cutoff date, which is why they can’t tell you about very recent events. You also can’t teach new facts to a model through conversation; that would require retraining the entire system. When you tell an AI something during a conversation and it “remembers” it later in that same chat, that’s not actual learning, but the context window at work. Start a new conversation, and the AI won’t recall anything from your previous sessions because each chat has its own separate context window. While using AI is relatively inexpensive for consumers, creating and updating models requires massive investments in computational resources. Finally, every response you receive is generated fresh based on learned patterns, not retrieved from a pre-written database of answers.
Perhaps the most important limitation to understand is AI hallucination, when models generate information that sounds authoritative but is partially or entirely incorrect. This is not a bug; it’s an inherent characteristic of how current AI systems work.
AI models are essentially sophisticated pattern-matching systems. They generate text by predicting what should come next based on patterns learned from training data. Sometimes, this process produces:
Always ask for sources and verify them independently through reliable databases or official websites. Request that the AI indicate when it’s uncertain about information rather than making confident assertions. Break complex questions into smaller, more specific parts to reduce the chance of compounded errors. Most importantly, use AI as a starting point for research and exploration, not as the final authority on essential matters. Think of AI as an incredibly knowledgeable research assistant who sometimes makes mistakes but can help you explore ideas, draft content, and find starting points for deeper investigation. Understanding hallucination means using AI wisely.
These concepts work together to explain the AI experience you encounter daily when you use ChatGPT, Claude, or other AI tools:
As AI continues to integrate into our work, education, and daily life, this vocabulary helps you make informed decisions about which tools to use, how to interact with them effectively, and what to expect from different AI systems.
The goal isn’t to become an AI expert, but to be an informed user who can harness these powerful tools while understanding their capabilities and limitations. Just as understanding basic internet concepts made you a more effective web user, grasping these AI fundamentals will help you understand the intelligent systems that are becoming part of our technological ecosystem. In our human-centred approach to AI, this knowledge enables us to use these remarkable tools effectively while maintaining realistic expectations about their capabilities and limitations.

Next in our series, we’ll explore how these concepts come to life in practice: from fine-tuning AI for specialised tasks and mastering prompt engineering, to understanding multimodal AI that works with images and text, agentic AI systems that can take action, and the vital choice between cloud-based and on-device AI processing.