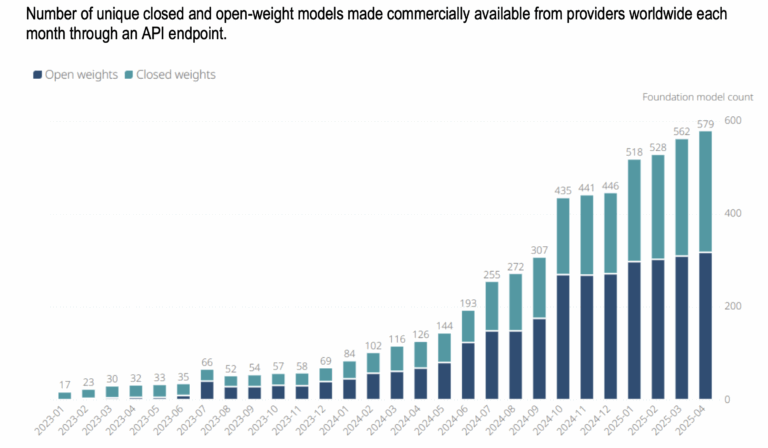
For years, the dominant story in artificial intelligence has been one of controlled access. A handful of companies, almost all of them American, built powerful AI systems and made them available to the world on their own terms: through their own platforms, their own APIs, at their own prices, under their own usage policies. You could use the technology, but you could never truly own it. You were always, in some sense, a tenant. That story is not over. But it is being complicated in ways that deserve serious attention, particularly for governments, institutions, and civil society organisations in countries that have been watching the AI race from the outside and are seeking to reclaim digital sovereignty. To understand why this matters, it helps to know what the alternative looks like. When we use a closed model like ChatGPT, Gemini, or Claude, the model never leaves the company’s servers. We send our input, their infrastructure processes it, and a response comes back. The company can change the model without notice, monitor usage, restrict topics, adjust pricing, or revoke access entirely, for any reason, including geopolitical decisions. We are renting access to a capability we do not own and cannot control. For an individual user, this is a minor inconvenience. For a government or institution that has built services and workflows around that model, it is a dependency with real strategic consequences. Before anything else, it helps to be precise about what is being discussed, because the term gets used loosely and the distinction matters. When a company releases a model with ‘open weights‘, it is making public the billions of numerical parameters that define how the model thinks and responds. These parameters are the product of training, an enormously expensive process of running vast datasets through computational infrastructure for months. Sharing the weights means sharing the finished product, not the process that created it. A useful analogy: a restaurant that shares its recipe is doing something valuable and generous. But sharing the recipe is not the same as telling you where the ingredients came from, how the kitchen was built, or what quality control decisions were made along the way. You can cook the dish. You cannot verify the dish’s full history. This distinction between ‘open-weights‘ and truly open source matters for AI governance. With open-weights, independent researchers can probe the model for biases, vulnerabilities, and failure modes. But the training data, the fine-tuning choices, and the safety decisions that shaped the model’s behaviour remain opaque. Openness, here, is real, but it is partial. With that caveat understood, the practical implications of open weights are still substantial, and for many countries they represent something genuinely new. The most prominent recent example is DeepSeek, the Chinese AI lab whose open-weight releases caused considerable disruption in early 2025. But framing this as a DeepSeek story misses what is actually happening. Open-weight models are the norm rather than the exception. Meta has been releasing open-weight models under its Llama family for some time, with each iteration becoming more capable. Alibaba’s Qwen series has become widely used across multiple regions. Mistral, a French company, has built its reputation largely on open releases. According to OECD and Global Partnership on AI analysis, more than half of all commercially available foundation models in 2025 were released with open weights (fully or partially). Even OpenAI, which spent years as the most prominent champion of the closed approach, released a family of open-weight models in August 2025, a concession to market and community pressure that its own CEO described as the company potentially having been on the ‘wrong side of history‘. What looked like a disruption is settling into the direction the industry is moving.Understanding ‘open weights‘
This is bigger than one company
Here is where the story gets practically important. For the roughly 150 countries that are far from the capabilities of the United States or China, developing a frontier AI model from scratch is unrealistic. The computing costs alone run into the hundreds of millions of dollars. The talent pools required take decades to build. The data infrastructure needed does not exist. This is simply the reality, and no amount of national AI strategy documents changes it.
What open-weight models offer is something different: the ability to participate in AI deployment and adaptation without needing to participate in AI development at the frontier. A government ministry in West Africa can download a capable open-weight model, run it on local servers, and fine-tune it on locally relevant data, covering local languages, local legal systems, and local health or agricultural challenges, without a single API call to a foreign company, without usage monitoring, without the risk of access being revoked for geopolitical reasons.
The evidence that this is already happening is real. DeepSeek’s market share across several African countries, including Ethiopia, Zimbabwe, Uganda, and Niger, reached between 11% and 14%, according to Microsoft‘s analysis from early 2026, figures that reflect genuine adoption rather than policy aspiration. Research published in Nature Health identified open-weight models as actively enhancing healthcare delivery in low- and middle-income countries through mobile applications and hybrid AI systems. South Korea, not a small country but one that was an AI consumer rather than a producer just a few years ago, launched a national sovereign AI initiative in 2025, built substantially on open-weight foundations, and had three domestically adapted models trending simultaneously on Hugging Face in February 2026.
The trend is consistent: open weights lower the barrier from ‘having access to AI‘ to ‘being able to shape AI for your own context’. For countries whose languages, legal traditions, and social contexts are underrepresented in the training data of major commercial models, this adaptability is not a minor feature, but a major one.
But the opportunity has conditions. Openness is a door, not a guarantee of passage. A country that cannot reliably power a data centre cannot run these models locally. A country without a pool of machine learning engineers cannot fine-tune them meaningfully. A country without data governance frameworks will struggle to curate the local datasets that make adaptation valuable. The infrastructure, talent, and policy prerequisites for actually using open weights are non-trivial, and they require the kind of sustained investment and capacity development that national AI strategies often describe but rarely fund concretely.

It would be naive to receive this as pure generosity, and it is worth being honest about the motivations involved.
For companies like Meta, the logic is partly competitive: by releasing capable open models for free, they help establish a baseline that makes proprietary models built on top of their infrastructure more attractive, including advertising systems, cloud services, and developer ecosystems. An open model that millions of developers build on is a distribution-and-influence play, not a charitable act.
For DeepSeek and Chinese labs more broadly, the motivations are layered. There is a commercial ecosystem argument: open releases create large user bases that can be directed toward paid products and services. There is a soft-power argument: Chinese AI capability, long dismissed in Western circles as derivative, has earned genuine credibility in the global developer community through the quality of its open-source releases. And there is an ironic twist worth noting: cybersecurity concerns and United States export controls on advanced semiconductors, designed to hobble Chinese AI development, appear to have forced Chinese labs to adopt leaner, more efficient training approaches, producing models that are cheaper to run and easier to share.
There is one layer that requires acknowledgment. The concerns around DeepSeek’s data handling practices are most relevant for those accessing it through its app or API, where the usual questions about data exposure and usage monitoring apply. For countries running the open-weight model locally on their own infrastructure, those concerns largely fall away. The more persistent question is around training data transparency, as we do not know precisely what data was used to build the model, which can matter for legal liability in commercial contexts. But for governments and institutions adapting the model for local public use, this is rarely a decisive obstacle.
The point is not to reject open-weight models from any particular source, but to approach them with the same critical governance lens that should apply to any foreign technology infrastructure.
It would be incomplete to discuss the open-weight movement without noting the history against which it stands.
OpenAI was founded in 2015 as a nonprofit, explicitly to ensure that artificial general intelligence would benefit humanity broadly rather than being captured by private interests. The founding premise was that AI was too important to be owned. What followed tells a different story. OpenAI used its nonprofit status to attract world-class researchers, raise hundreds of millions in funding, and build foundational technology, then converted to a for-profit structure and is today valued at around USD 300 billion.
Anthropic was founded by former OpenAI researchers who took that same nonprofit-funded knowledge and experience with them when they left to start their own commercial venture, raising billions from Amazon and others. Elon Musk co-founded OpenAI, later sued it for abandoning its nonprofit mission, and simultaneously founded xAI, his own for-profit AI company. In each case, the nonprofit foundation did the hard early work of building credibility, attracting talent, and advancing the science. The private companies that emerged from it captured the value.
DeepSeek, by contrast, never claimed a civilizational mission. It presented itself as a technology company that wanted to build capable AI. And yet it is DeepSeek, along with Meta, Mistral, and Alibaba’s Qwen team, that have actually placed capable technology in the hands of anyone who wants it. The consequences go beyond business. When the most prominent voices in AI spend years wrapping commercial ambition in the language of public benefit, that language loses its meaning. The ones who pay the price are not the tech billionaires, but the UN agencies, the civil society organisations, and the smaller governments who actually mean it when they say AI should serve the public good, and who now have to fight to be believed.
This is worth naming plainly, not as a point of cynicism, but as a reason to be precise about what open-weight releases actually represent. They are not altruism. But they are, functionally, more useful to more people than most of the altruism-branded alternatives.
The commercial AI ecosystem is still in early formation, and the decisions made in the next few years about standards, interoperability, and governance will shape who has real agency in AI for a long time.
For governments and institutions that have not been at the center of the AI race, three things are worth doing:
The AI race has largely been narrated as a story about two superpowers, and everyone else as an audience. Open weights do not change that underlying structure. But they do create real openings, practical, legal, and political, for countries that move with clarity about what they want and what they are willing to build. That is a better starting position than most expected to have.
Author: Slobodan Kovrlija