At a recent AI ethics conference in Doha, the conversation about smart cities followed a predictable pattern. Speakers talked about optimisation, efficiency, and seamless integration of AI into urban infrastructure. Yet when pressed for concrete examples of how these systems work in practice, the discussion remained abstract. This gap between vision and reality reveals something important: AI-powered smart cities are being built faster than we can articulate what they actually do and who they serve. The promise is compelling. AI systems can reduce traffic congestion, lower energy consumption, improve public safety, and allocate resources where they’re needed most. Cities from Singapore to Barcelona are deploying machine learning algorithms that manage everything from waste collection to emergency response. But beneath the techno-optimist rhetoric lies a fundamental tension that urban planners and policymakers are only beginning to confront. The first challenge revolves around how we define these systems. When does a smart city’s AI cross the line from service into surveillance? Consider traffic management systems that use computer vision to optimise signal timing. These neural networks don’t simply count cars; they classify vehicle types, estimate speeds, predict congestion patterns, and increasingly, identify individual vehicles through license plate recognition. AI doesn’t distinguish between optimising traffic flow and creating a database of movement patterns. The algorithm does both simultaneously. What makes this particularly concerning is that AI systems don’t passively observe. They actively interpret what they see based on their training data. Computer vision algorithms decide what counts as suspicious behaviour, what constitutes a crowd versus regular foot traffic, and which patterns warrant alerts to authorities. These are judgment calls encoded into the model during training, often using datasets collected in entirely different contexts. An AI trained on footage from Western cities may misinterpret cultural norms when deployed in Asia, Africa, or the Middle East. Prayer gatherings might be flagged as unusual assemblies. Market haggling could trigger fraud alerts. Traditional clothing might confuse person-detection algorithms. Singapore’s Smart Nation initiative offers the clearest example of AI surveillance at scale. The city-state has deployed an extensive network of cameras feeding real-time data to machine learning systems that monitor crowd density, predict maintenance needs, and identify potential security concerns. These are not just simple motion detectors; they are sophisticated AI models capable of recognising individuals, tracking them across multiple cameras, and building profiles of behaviour patterns over time. Citizens benefit from reliable services and well-maintained infrastructure. AI can predict when an escalator is likely to fail, reroute buses around accidents before traffic backs up, and alert cleaners to areas that need attention. These are genuine improvements to urban life. They also require accepting that neural networks are constantly analysing your movements, learning your routines, and making inferences about your behaviour. The critical question isn’t whether AI surveillance is happening; it clearly is. The question is whether residents have meaningful input into how these algorithms operate, what data they collect, how long it’s retained, and who can access it. In Singapore’s case, the answer is largely no. The government argues that this trade-off between privacy and efficiency is acceptable given the city’s unique context and social contract. But this model is now being exported to cities worldwide, often without the same cultural consensus or democratic oversight. Dubai presents another variation. The city’s smart initiatives rely heavily on facial recognition AI deployed in airports, government offices, and increasingly in public spaces. The stated goal is convenience. The algorithms promise faster passport control, reduced wait times, and frictionless access to services. The unstated reality is an AI system that can track residents and visitors across the city with remarkable accuracy. For a city built primarily on expatriate labour, where citizenship is restricted and rights are unequal, the implications are significant. AI doesn’t just observe inequality, it enforces it through differential access and monitoring. The second tension emerges when machine learning moves from observation to decision-making. Predictive algorithms are increasingly determining where cities invest in infrastructure, deploy services, and allocate police resources. This is where AI can entrench historical inequalities rather than solve them. Algorithmic city planning relies on training data that reflects past decisions and outcomes. If historical data shows that specific neighbourhoods generated more service requests, more maintenance calls, or more police reports, the AI model will learn to direct resources accordingly. The algorithm identifies patterns and extrapolates them into the future. This sounds rational until you consider why those patterns exist in the first place. Neighbourhoods that were historically neglected may show higher infrastructure failure rates because they received less maintenance. The AI learns that these areas are “high maintenance” and may actually deprioritise them to optimise overall system efficiency. Areas with heavier police presence will naturally generate more crime reports in the training data, creating a feedback loop where the algorithm recommends continued over-policing. The machine learning model doesn’t understand historical context or structural inequality. It simply finds correlations in the data and assumes they represent ground truth. This dynamic is extensively documented in the Atlas of AI by Kate Crawford and Automating Inequality by Virginia Eubanks, which analyse how data-driven systems can reproduce and amplify social divides rather than correct them. What makes this particularly insidious is scale and speed. A human planner might make biased decisions, but they can only process so much information and make so many choices in a day. An AI system can apply its learned biases to millions of resource allocation decisions instantaneously, across every neighbourhood, every service request, every infrastructure investment. And because the recommendations come from “data-driven” algorithms, they carry an aura of objectivity that makes the bias harder to challenge. How do you argue with a neural network that has analysed millions of data points? This isn’t hypothetical. Several US cities have experimented with predictive policing algorithms that analyse crime data to identify areas requiring increased patrols. Studies found that these systems consistently targeted minority neighbourhoods, not because crime was objectively higher there, but because those areas had historically been subject to more intensive policing and therefore generated more arrests in the training data. The AI learned to reproduce the pattern and recommend more policing, leading to more arrests and further reinforcing of the model’s predictions. The algorithm created a self-fulfilling prophecy of over-policing. The risk is that AI transforms these historical biases into architectural permanence. When a machine learning model recommends building a new hospital, extending a metro line, or increasing surveillance in certain areas, it’s making choices about the city’s physical form. These are decisions that will shape urban life for decades. If the data feeding those decisions reflects discrimination, redlining, or unequal resource distribution, the AI automates inequality at scale and enshrines it in concrete.When AI learns to watch
When AI becomes the urban planner
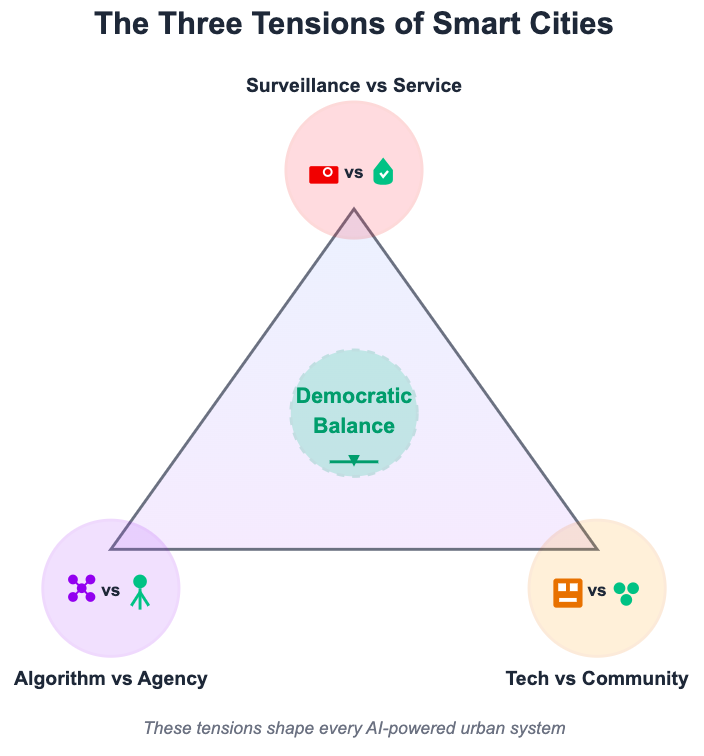
The third dimension is the most challenging: who decides what problems the AI solves and what data it learns from? Smart city initiatives are typically developed through partnerships between municipal governments and technology companies. AI models are trained on datasets selected by engineers and data scientists. The residents who will live with these systems are rarely consulted about what the algorithms should optimise for, what trade-offs are acceptable, or what values should guide the AI’s decision-making.
This creates a fundamental misalignment. Technologists might train an AI to optimise traffic flow, measured by reduced average commute times. But residents might prioritise pedestrian safety, noise reduction, or maintaining neighbourhood character, all of which are values harder to quantify and therefore often excluded from the algorithm’s objective function. The AI becomes very good at solving problems nobody asked it to solve, while ignoring the issues communities actually care about.
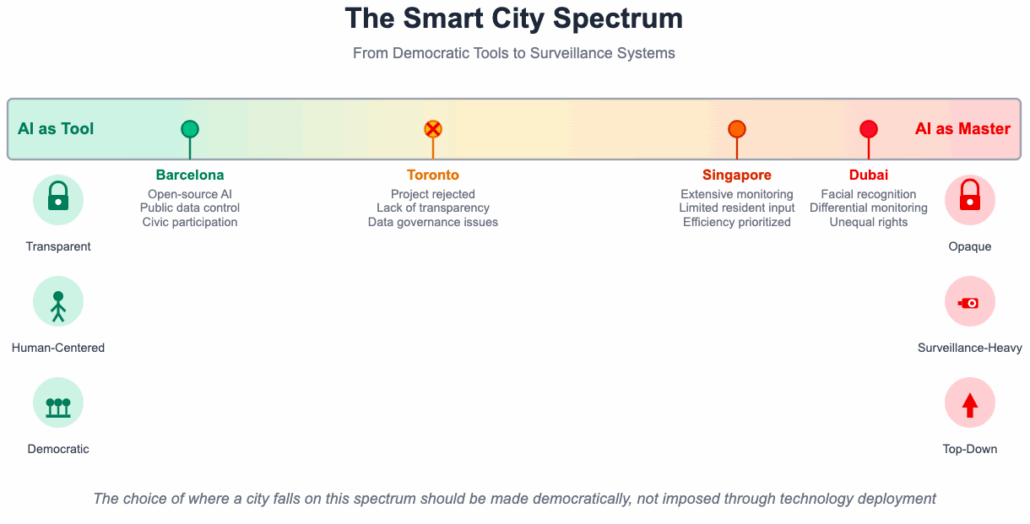
The collapse of Sidewalk Labs’ Toronto project is a good example. In 2017, Google’s sister company proposed building a sensor-laden neighbourhood on Toronto’s waterfront. The vision included AI-powered adaptive traffic lights, algorithmic resource allocation, underground robot delivery systems, and comprehensive data collection about how residents used public space. Machine learning models would optimise everything from energy usage to snow removal.
Community pushback focused on data governance and algorithmic transparency. Who would own the information generated by Toronto residents going about their daily lives? How would the AI models be trained? What would they optimise for? Could the algorithms be audited? Would law enforcement have access to the predictive models? Sidewalk Labs struggled to provide satisfactory answers, partly because the project’s value proposition relied on collecting vast amounts of data to train increasingly sophisticated AI systems. When it became clear that residents would not accept this bargain without meaningful control over the algorithms, the project died.
The Toronto case matters because it represents a rare instance where a community successfully rejected an AI-driven smart city proposal before implementation. In most cases, especially in the Global South, machine learning systems are deployed without comparable public debate. International development funding often comes with requirements to adopt specific AI platforms. Indigenous communities and low-income neighbourhoods find themselves living in algorithmically managed cities they had no role in designing, with AI systems optimising for metrics they didn’t choose as priorities.
Barcelona offers a contrasting approach that centres human agency in AI deployment. Under the leadership of Chief Technology Officer Francesca Bria, the city developed a digital sovereignty agenda that treated AI as a tool to serve democratically determined goals rather than an autonomous decision-maker. As part of its DECODE and Digital City projects, Barcelona deployed machine learning for air quality monitoring, noise mapping, and traffic analysis, but with strict limits on what the algorithms could do with the data. Crucially, the city favoured open-source AI models over proprietary black boxes. This allowed independent audits of how the algorithms made decisions and what biases might be encoded in their training. Barcelona required that any data generated by public infrastructure remain under public control and that AI systems optimise for goals chosen through civic participation rather than technical convenience.
The Barcelona model demonstrates that AI in cities doesn’t have to mean surrendering decision-making to algorithms. Machine learning can augment human judgment without replacing it. An AI model might analyse traffic patterns and suggest interventions, but urban planners, accountable to elected officials and residents, make the final calls based on community values, not just algorithmic efficiency.
This human-centred approach requires acknowledging what AI does well and what it cannot do. Neural networks excel at finding patterns in large datasets, making predictions based on historical trends, and processing information at scale. They cannot understand context, make value judgments, or account for goals that weren’t encoded in their training. An AI optimising for traffic flow doesn’t understand that some neighbourhoods value slow streets where children can play. An algorithm predicting infrastructure needs doesn’t comprehend the cultural significance of public spaces that might appear ‘underutilised’ in the data.
The key is keeping humans in the loop at decision points that matter. AI can surface insights and recommendations, but people should determine which insights are relevant, which recommendations align with community values, and when algorithmic suggestions should be overridden by local knowledge. This requires transparency about how the models work, what data they use, and what they’re optimising for. It requires training for city officials in AI literacy so they can meaningfully evaluate algorithmic recommendations. Most importantly, it requires genuine mechanisms for resident input into what the AI systems should prioritise.
The term “smart city” itself may be part of the problem. It suggests that urban life can be optimised through better AI-driven information processing, reducing the complexity of human communities to data flows and algorithmic predictions. This framing privileges everything that can be easily measured and optimised while excluding what makes cities genuinely livable, such as social trust, cultural vitality, democratic participation, and the unplanned encounters that make urban life dynamic.
There’s nothing inherently wrong with using AI to improve urban services. Machine learning can reduce commute times and emissions, prevent infrastructure failures before they happen, and optimise energy usage. These are real benefits. But they come with trade-offs that are often hidden in technical implementation and AI’s training process.
The surveillance question won’t be resolved through better privacy policies alone, though those are necessary. It requires a broader conversation about what kind of urban life we want AI to enable. Do we want cities where algorithms anticipate our needs before we articulate them, where neural networks optimise every interaction for efficiency? Or do we want cities that preserve space for spontaneity and privacy, where residents can move through public space without being constantly analysed by computer vision systems? Different communities will answer differently based on their values, history, and political context. What matters is that the choice remains a choice, made democratically rather than imposed through AI systems whose training data and objective functions reflect Silicon Valley assumptions about what cities should optimise for.
The danger isn’t the technology itself, but the assumption that AI-driven solutions are politically neutral, that algorithmic optimisation serves everyone equally, and that efficiency is always worth the price we pay in autonomy and privacy. Machine learning models are trained on data that reflects existing power structures and historical inequalities. Without deliberate intervention, AI will reproduce and amplify those patterns at scale.
As cities around the world rush to deploy AI systems, these questions can’t be postponed until the algorithms are already making decisions and the neural networks are already trained. Once the machine learning infrastructure is in place and operational, changing course becomes exponentially more complicated. The models have learned their patterns, the data pipelines are established, and institutional processes have adapted to algorithmic recommendations.
The time for democratic deliberation about AI in cities is now, while we still have the option to design systems that serve residents rather than simply managing them. That means insisting on transparency about how the algorithms work, meaningful participation in determining what they optimise for, and preserving human judgment at decision points that shape urban life. This debate belongs not just to city councils but to global dialogues on AI governance. Smart cities should be places where AI augments human agency rather than replaces it, and where algorithms provide tools for democratic decision-making rather than acting as black boxes that generate instructions. AI technology can serve people, but only if we insist that serving people, not optimising systems, remains the goal.